In this mini-series of blogs I discuss a technique to provide fast read time to a consumer facing website using a read model architecture. In this first article I explain the problem and proposed solution.
Problem to solve
I've recently looked at a client application which relies on a third party (closed source) backend.
The architecture follows this structure:
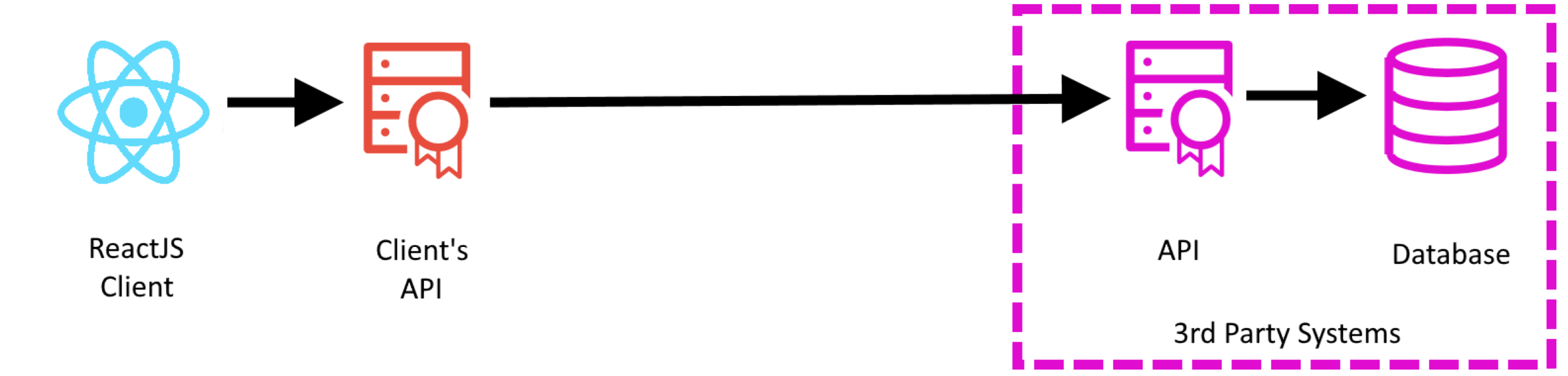
The consumer would interact with the website (ReactJs), which would make requests to the clients Api for data. The clients Api would retrieve this data from a third party Api - which in turned retrieve it from a database.
We found that, on occasion, that the third party Api would stall while retrieving the data the database. Normal operation was in the low tens of milliseconds. Yet occasionally, the Api would take upwards of a second.
And while this wouldn't be a major problem for a low volume Api, this was quite a heavily used Api. So while one call would take upwards of a second - further requests for the same resource would start to build up. Ultimately this could even lead to the web server (IIS) becoming unavailable.
While previous work to cache the result from the third party Api had helped, ultimately the cache would expire and request would need to be made to the third party Api. So while it reduced the likelihood - it didn't eradicate the problem.
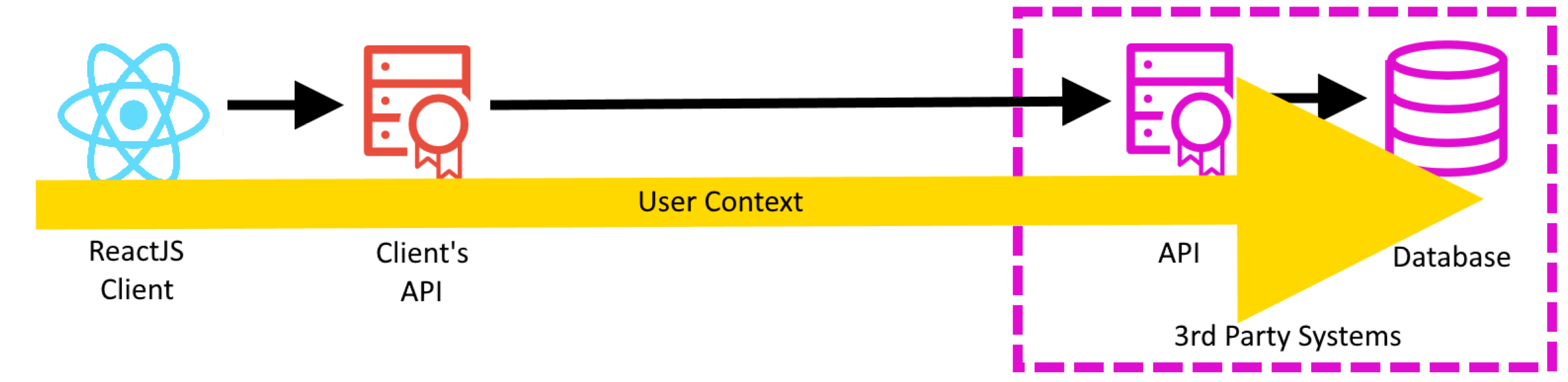
The central problem was removing the interacting with the third part Api from the consumers execution context.
Read Models
Enter the Read Model.
A Read Model is part of the CQRS Pattern.
The idea behind CQRS is to separate the Command (create, update and delete) from the Query (read) activities. Generally it is used to improve performance of reads using eventual consistency.
And in this instance, it works great for separating the consumer from the third party Api.
Solution Overview
So the new solution looks like this;
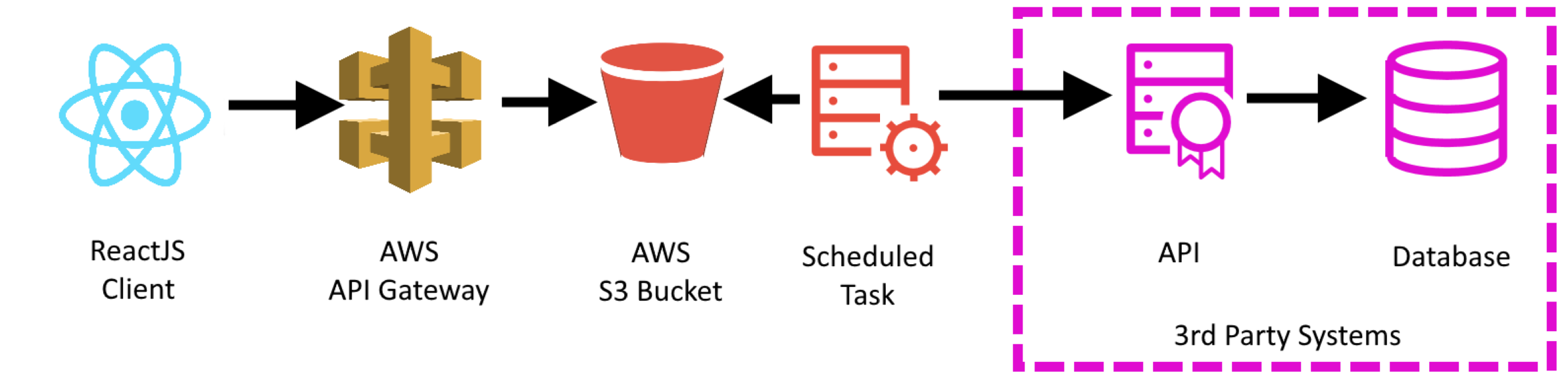
This gives us two distinct halves - the half that updated the Read Model (the S3 bucket) and the half that reads from the Read Model.
I'll talk about the benefits and consequences further below - but for now lets just talk through the solution.
The key to this working is that the "payload" being provided to the consumer is just a JSON object - which can go unchanged for anywhere between minutes and hours.
In this solution, I've separated the responsibility for creating that JSON object and serving of the JSON object to the consumer.
To create the JSON object, I'll be using some form of scheduled task (maybe a windows service on a timer, or a cron based task). This scheduled task makes the same call into the third party Api as previously. It then saves that data as a JSON file on the S3 "Read Model" bucket. This task is completely independent of the consumer - thus, even if the third party is stalling, it is only the writer which is affected.
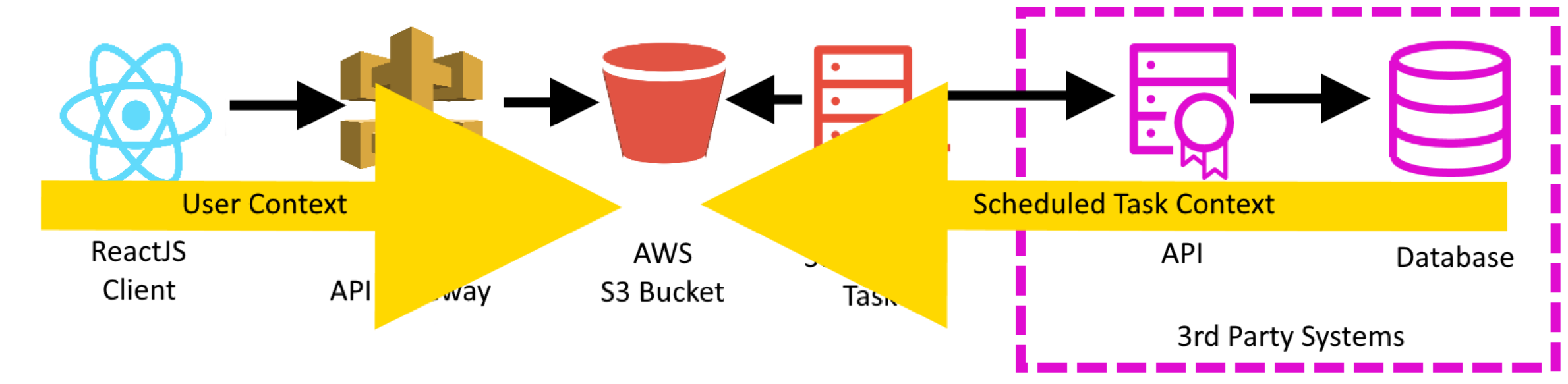
To serve the JSON object to the consumer, I use an AWS Api Gateway over the S3 "Read Model" bucket. It will simply serve the latest version of the file to the consumer.
I chose to use an AWS Api Gateway as an intermediary as it gives me flexibility to change the implementation later - for example if I used Redis rather than S3.
An Api Gateway is also a useful method of consolidating Api backends - rather than having the consumer being aware of the various Api endpoints. So this would allow me to "hide" the clients existing Api - proxy the calls through - yet present a single Api to the consumer.
Benefits
The primary benefit is that we are separating the user from the problematic backend. The user request should be very fast - faster than the previous version.
The Api Gateway & S3 also provide a means of expanding in the future.
Consequences
This does make the solution more complex - and may not be as obvious at first glance how it works. It adds additional technologies to the solution - so there will be the overhead of the team getting to grips with them.
There is also the danger of "stale" data. If the scheduled task stops updating the S3 bucket, it won't be obvious from the frontend that there is a problem. The upside is that the frontend will continue to work - just with stale data. To provide a good user experience, you could include a timestamp in the JSON and have the frontend inform the user that the data was stale.
Deploying the solution
In the next article, I will provide instructions on how to create this in AWS.