Back around this time last year, I wanted to re-write how I handled my blog content on red-folder.com
When I re-wrote red-folder.com I moved my blog content (previously hosted on Blogger & LinkedIn) to be under red-folder.com/blog. This was to properly capture my thoughts in the one place.
At the time when I did this - as a temporary act - I just included the blog markdown within the red-folder.com codebase. While this worked, it was a painful (and slow) exercise to add a blog article as it involved a full release of the red-folder.com website - and while this isn't a major problem due to the VSTS Continuous Delivery pipeline I have setup for it - it isn't without friction;
- I use my laptop as a build agent - so it has to be on and available
- The red-folder.com Continuous Delivery pipeline isn't super quick (around 5 minutes due to a number of regression tests)
So I decided to write something inspired by the (at the time) docs.microsoft.com. The Microsoft Docs site had had a major revamp and used Github to store Markdown and code (later released as DocFX) to take that markdown and produce the html content.
After various distractions, I've finally got round to getting the initial version of this live. This blog talks a bit about the motivation, how it work and the supporting processed round it.
Motivation
I'll be blunt, this is a vanity project.
There are plenty of really good blog platforms out there.
But sometimes you get an itch and have scratch it. In this instance I though it would be a really cool use of Azure Functions and Github. I thought it was another great oppertunity to build a CD pipeline through VSTS. And, if no one looks at the code too hard, a good oppertunity to show off my development capabilities.
How the solution works
So, this is how it work;
I create a new blog and commit to the https://github.com/Red-Folder/red-folder.docs.production repo.
I work to a number of conventions for a new blog;
- Content for a blog is grouped in a folder (generally named the same as the url that will be used for the blog)
- blog.json - a json file with relevant meta data about the blog - stuff like the Url, title, short description, keywords, etc
- blog.md - the markdown for the blog article
- Any images for the blog are stored in the at same folder (.png, .jpg, .gif).
On push to the repo, Github is configured with a webhook to notify an Azure function of the new commits.
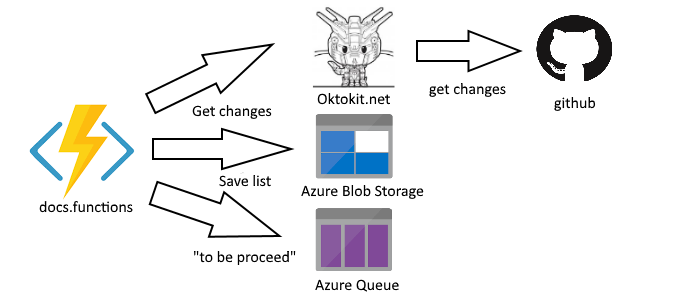
That Azure function uses the Octokit.net library (a project that I've contributed before) to get a list of the added/ removed/ updated files as part of the commit. It produces a list of changes that need to be processed. I save the list as a serialised object to Azure Blob storage, then put a record into a "to be processed" Azure Queue.
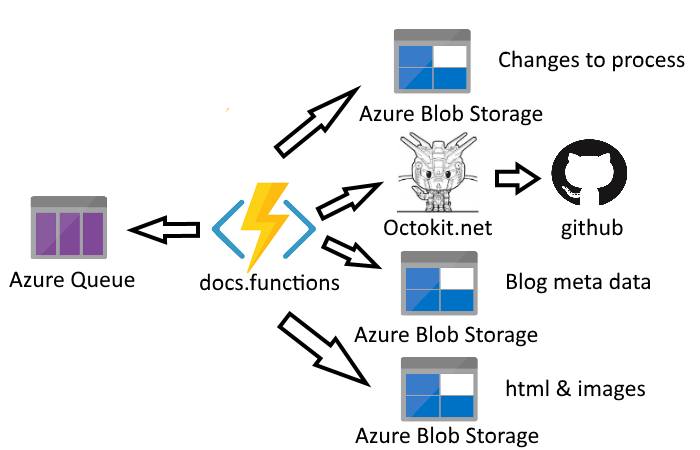
A second Azure function monitors that queue. It is responsible for processing the list of changes to:
- Maintain a list of available blogs and their meta data
- Transform the markdown into html and make available via Azure Blog storage
- Copy images and make available via Azure Blog storage
At the end of its run, the Azure function emails me a summary of actions (along with errors) via SendGrid.
The blog meta data is them made available via another Azure function - operating in a RESTful manner.
The RESTful interface is used by red-folder.com to query available blogs meta data. Red-folder.com uses that data to build the blog homepage.

On selection of a specific blog, the blog meta data includes the Azure blob url for the relevant html, red-folder.com presents this html to the user. The html will reference any images directly at the Azure blog url (which is presented via Cloudflare as content.red-folder.com).
And the whole lot is using Application Insights for errors and metrics.
This should mean (in theory); I write the blog, commit it, wait for an email (normally seconds) and then can happily browse it on red-folder.com. Easy.
A fair amount of complexity
As with any simple idea, there is a lot more complexity in the execution.
The code for the Azure functions can be found here
There is a considerable amount of logic put into transforming the Markdown correctly, handling blog removals and updates, and generally just gluing it all together.
There are a number of simplifications I could apply going forwards (see further work) - but for now it seems to hold together. There are bound to be some edge cases in which it struggles.
One problem I did hit quite late in the day was the size limit in Azure Queue - which is something I've studied before as part of the Azure Architecture certification. And because of that study, I knew the best option was to save the payload (in the case, the list of files to be changed) to Azure Blob storage, then include a reference (name of the blob) in the Azure Queue message - easy when you know how.
The supporting process
The supporting process I put in place for this project really saved me.
Early in the project, I'd built a Continuous Delivery pipeline through VSTS.
Not only did it do the standard build, unit test, package and deploy steps. I also added full acceptance tests.
I deployed the package code to a staging environment (a different Azure account, a different github repo), then proceed to run through a number of acceptance tests to validate correct behavior:
- Adding a new blog
- Deleting a blog
- Amending an image on an existing blog
- Amending blog content for an existing blog
This pipeline has been a considerable life saver for me after picking the project up again after long periods of inactivity. It has really helped to reduce the ramp up period each time I revisited the code.
Further work
There is definitely further work that can be done.
I'd like to simplify some of the logic so that even more of it is convention driven (thus removing logic from the code).
There is also more refactoring that can be applied to make the codebase easier to follow.
But that's all for another day.
At the moment, my "spare time" is diminishly short - so I'll get it out and get the value.
Fingers crossed it works as expected.